Deepseek Ai: The Google Strategy
페이지 정보

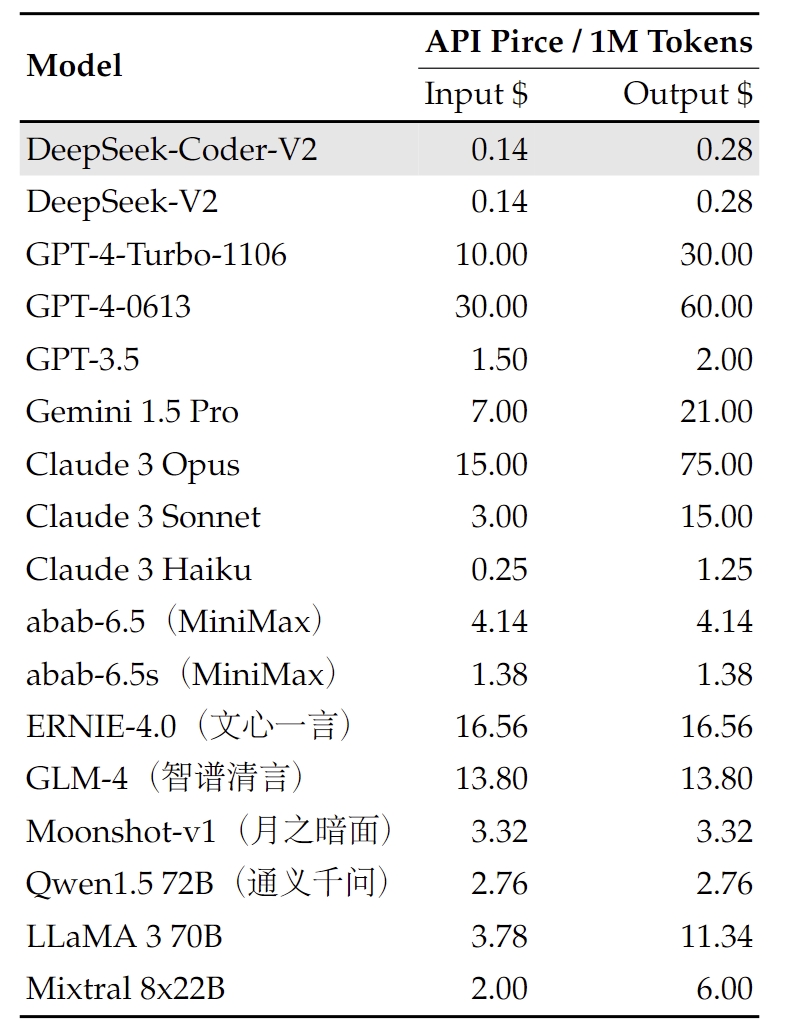
본문
Assuming we can do nothing to cease the proliferation of extremely succesful models, one of the best path ahead is to use them. It’s just one in all many Chinese firms working on AI to make China the world leader in the sphere by 2030 and greatest the U.S. Section 3 is one area the place studying disparate papers is probably not as useful as having more sensible guides - we suggest Lilian Weng, Eugene Yan, and Anthropic’s Prompt Engineering Tutorial and AI Engineer Workshop. Expores a marquee paper from UC Berkeley on this space and dives into Hugging Face’s Gradio framework for constructing Web-AI applications. The large concern for the US AI corporations and their buyers is that it appears that building huge information centres to home multiples of expensive chips might not be essential so as to attain sufficiently profitable outcomes. Larger data centres are operating more and sooner chips to practice new models with bigger datasets.
 The folks at IDC had a take on this which, as published, was concerning the $500 billion Project Stargate announcement that, once more, encapsulates the capital outlay wanted to practice ever-larger LLMs. The firm says it developed its open-supply R1 mannequin using round 2,000 Nvidia chips, just a fraction of the computing energy generally thought essential to train comparable programmes. Ross mentioned it was incredibly consequential but reminded the viewers that R1 was skilled on round 14 trillion tokens and used round 2,000 GPUs for its coaching run, both similar to coaching Meta’s open source 70 billion parameter Llama LLM. Chinese AI startup DeepSeek made fairly a splash final week with the release of its open source R1 large language model (LLM). R1 was a transparent win for open supply. The bigger point, Ross said, is that "open models will win. Within the cyber security context, close to-future AI models will be able to constantly probe methods for vulnerabilities, generate and take a look at exploit code, adapt assaults based on defensive responses and automate social engineering at scale. These communities might cooperate in creating automated tools that serve each security and safety research, with objectives equivalent to testing fashions, generating adversarial examples and monitoring for indicators of compromise.
The folks at IDC had a take on this which, as published, was concerning the $500 billion Project Stargate announcement that, once more, encapsulates the capital outlay wanted to practice ever-larger LLMs. The firm says it developed its open-supply R1 mannequin using round 2,000 Nvidia chips, just a fraction of the computing energy generally thought essential to train comparable programmes. Ross mentioned it was incredibly consequential but reminded the viewers that R1 was skilled on round 14 trillion tokens and used round 2,000 GPUs for its coaching run, both similar to coaching Meta’s open source 70 billion parameter Llama LLM. Chinese AI startup DeepSeek made fairly a splash final week with the release of its open source R1 large language model (LLM). R1 was a transparent win for open supply. The bigger point, Ross said, is that "open models will win. Within the cyber security context, close to-future AI models will be able to constantly probe methods for vulnerabilities, generate and take a look at exploit code, adapt assaults based on defensive responses and automate social engineering at scale. These communities might cooperate in creating automated tools that serve each security and safety research, with objectives equivalent to testing fashions, generating adversarial examples and monitoring for indicators of compromise.
Where I feel everyone is getting confused though is when you might have a model, you'll be able to amortize the cost of creating that, then distribute it." But fashions don’t keep new for long, meaning there’s a durable appetite for AI infrastructure and compute cycles. In 2019, Liang established High-Flyer as a hedge fund focused on creating and using AI buying and selling algorithms. One example of a query DeepSeek’s new bot, using its R1 model, will reply differently than a Western rival? The previous two roller-coaster years have provided ample proof for some knowledgeable speculation: reducing-edge generative AI models obsolesce quickly and get replaced by newer iterations out of nowhere; main AI technologies and tooling are open-source and main breakthroughs more and more emerge from open-source improvement; competition is ferocious, and business AI firms proceed to bleed cash with no clear path to direct revenue; the idea of a "moat" has grown more and more murky, with skinny wrappers atop commoditised models providing none; in the meantime, critical R&D efforts are directed at reducing hardware and resource requirements-no one needs to bankroll GPUs ceaselessly. Australia should take two speedy steps: faucet into Australia’s AI security community and set up an AI security institute. Australia’s growing AI security neighborhood is a strong, untapped resource.
Pliny even launched a complete community on Discord, "BASI PROMPT1NG," in May 2023, inviting other LLM jailbreakers in the burgeoning scene to hitch together and pool their efforts and techniques for bypassing the restrictions on all the new, emerging, leading proprietary LLMs from the likes of OpenAI, Anthropic, and different energy players. The prolific prompter has been finding methods to jailbreak, or take away the prohibitions and content material restrictions on leading massive language fashions (LLMs) such as Anthropic’s Claude, Google’s Gemini, and Microsoft Phi since final year, allowing them to provide all sorts of attention-grabbing, dangerous - some might even say dangerous or DeepSeek harmful - responses, resembling how you can make meth or to generate images of pop stars like Taylor Swift consuming medicine and alcohol. The corporate hasn’t built many shopper products on high of its homegrown AI model, Claude, and as an alternative depends primarily on selling direct access to its model through API for different companies to build with.
If you are you looking for more in regards to Deepseek FrançAis visit the web site.
- 이전글Guide To Ultra Lightweight Folding Electric Wheelchair: The Intermediate Guide Towards Ultra Lightweight Folding Electric Wheelchair 25.03.05
- 다음글You'll Never Guess This German Shepherd Life Expectancy's Tricks 25.03.05
댓글목록
등록된 댓글이 없습니다.